Inventeringen följer många olika artgrupper, arter och strukturer så det finns möjlighet att utföra ett stort antal analyser. Det finns dock ingen möjlighet att i detalj utvärdera alla analyser som presenterats i de publicerade rapporterna. Jag har valt att titta närmare på två av de analyser som presenterats i de flesta rapporterna, busktäckning och förekomst av vass, plus en genomgång av möjligheten att göra analyser från den separata artinventeringen i småprovytorna. Syftet med det här avsnittet är att försöka på enklast sätt analysera fenomenen för att sedan jämföra och se ifall de slutsatser som presenterats i rapporterna överensstämmer med vad jag finner.
Resultat och tolkningar från analyser utförda inom den Stråkvisa inventeringen är publicerade i flera rapporter, se exempelvis (Larsson and Ottosson 2021), (Peilot et al. 2020). Det har dock varit svårt att i detalj förstå hur analyserna utförts. Vissa steg av analyserna har utförts i Excel, ofta i samma excelfiler där datat finns lagrade. Andra analyssteg, exempelvis mer avancerade analyser av trender är dock gjord i annan programvara och där finns varken kod tillgänglig eller någon fullständig statistisk metodbeskrivning.
I de publicerade rapporterna har jag uppmärksammat tre aspekter i analyserna som går att förbättra: (1) Vilken nivå i inventeringsdesignen som skall hanteras som replikat, den nivå man använder för att beräkna skattningsosäkerhet. (2) Hur man utför förändrings- eller trendanalyser när man har permanenta provytor?. (3) Hur man utför skattningar på proportioner, exempelvis andel av viss vegetationstyp på stränderna?
Den stråkvisa inventeringen har använt en klusterdesign då man först valt ut ett antal lokaler och sedan fler stråk inom varje lokal. Detta skapar ett rumsligt statistiskt beroende mellan stråken inom lokalerna och gör att de enskilda stråken inte bör användas som oberoende replikat i analyserna. Om man gör det så underskattar man de skattade varianserna och konfidensintervall och signifikanser blir inkorrekta. Mer korrekt är att använda lokaler som replikat eller som det ofta kallas, primary sampling unit. Det finns olika metoder man kan använda för att hantera klustrade data så att variansberäkningarna blir korrekta. I den här utvärderingen har jag valt den enklaste, att aggregera alla data till lokal. Praktiskt betyder det att analyserna är gjorda på medelvärden av trakter inom varje lokal. I de publicerade analyser jag kunde följa hur precisionen var beräknad hade stråken använts som primary sampling unit. Det betyder att precisionen kan vara överskattad i vissa analyser.
Inventeringen använder permanenta provytor eller ska man kanske säga permanenta stråk. Genom att märka upp startpunkterna kan exakt samma stråk inventeras vid varje inventeringstidpunkt. Det skapar ett tidsmässsigt statistiskt beroende mellan mätningarna inom varje stråk och lokal. Till skillnad från förra punkten med rumsliga beroenden så underlättas det för analytikern att detektera trender om man tar hänsyn till de tidsmässiga beroenden som finns i en permanent design. Att göra en förändringsanalys mellan två tidpunkter är jämförelsevis enkelt. Vill man skatta trender med flera avläsningstillfällen behöver man använda mer avancerade modeller.
Många av analyserna i de publicerade rapporterna har analyserat proportioner, exempelvis busktäckning per stråkmeter. Proportioner är dock mer komplicerade att skatta. För att skatta proportioner korrekt behöver man skatta täljaren och nämnaren i proportionen separat. Sedan beräkna proportionen. Beräkningen av skattningsvariansen innehåller sedan även en kovarians som måste inkluderas. Ett vanligt misstag är att man utför skattningen genom att beräkna medelvärden och varians direkt från proportionerna. Det leder både till ett systematiskt fel i själva skattningen och ett fel i variansberäkningen. Det systematiska felet uppstår genom att stränderna får fel viktning. Långa stråk representerar stränder med större area och de får då samma vikt som mindre stränder. Om fenomenet man analyserar varierar med strandstorlek kommer skattningen bli inkorrekt.
För de olika frågeställningarna gör jag först en deskriptiv sammanställning av resultaten. Jag utför analyserna i programspråket R(R Core Team 2023) och programkoden kan ses i webversionen av dokumentet under flikarna code. Jag har försökt utföra en så enkla analyser som möjligt och jag presenterar inga formler för analyserna.
Jag har heller inte försäkrat mig om att allt data är kvalitetssäkrat. Jag har observerat en antal felskrivningar, men jag tror inte de påverkar dessa resultat nämnvärt. Men dessa analyser bör inte användas direkt i andra sammanhang utan validering.
6.2 Busktäckning
Busktäckning mäts i det en meter breda stråket. Inom varje stråk har start och slutpositionerna för varje buskart (eller släkte) registrerats. Genom att summera förekomsterna kan den totala täckningen beräknas för varje stråk. Täckningen kan beräknas för enskilda arter eller för alla buskar som grupp.
Code
#! echo: falselibrary(tidyverse)library(janitor)library(readxl)library(mgcv)library(marginaleffects)library(broom)# Läs in senaste stråkdatatstrakdata <-read_excel("/Users/hans/Documents/Vanern_utvardering/data/Grunddatabas tom 2020 (2021-01-10).xlsx", sheet =9) |> janitor::clean_names()# Senaste artdatatdata4 <- data4 <-read_excel("/Users/hans/Documents/Vanern_utvardering/data/vegrutor_fix.xlsx", sheet =2, skip =4) |> janitor::clean_names()# Pivotera artdatat till lång form och behåll aal nollförekomstervegdata0 <- data4 |>pivot_longer(cols =5:567,names_to =c("lokal", "straknr", "ar"),names_pattern ="x(.*)_(.*)_(.*)",values_to ="n_rutor",values_drop_na =FALSE) |>transmute(lokal =as.numeric(lokal),straknr =as.numeric(straknr),strak_id = glue::glue("{lokal}_{straknr}"),ar =as.numeric(glue::glue("20{ar}")), vetensk_namn, svenskt_namn,funk_grupp = ort_trad_vedartad_busk,n_rutor =coalesce(n_rutor, 0)) |>arrange(lokal, straknr, ar, svenskt_namn)
Code
# Designobjekt för stråken# Vilka stråk är inventerade vilka år# Detta behövs så att nollvärden kan skapas för de år som är inventerade men saknar buskarstrakdata_inv_ar <- strakdata |>distinct(lokal, straknr, strak_id, ar) |>arrange(lokal, straknr, strak_id, ar)# Välj ut enbart artgrupp buskar# Beräkna total täckningsgrad för buskar# Aggregera täckning för varje stråk och årbuskar_tackning_strak_ar <- strakdata |>filter(artgrupp %in%c("buske", "Buske")) |># Felstavning artgruppmutate(len = stopp_m - start_m) |># Beräkna total täckningsgradselect(lokal, straknr, strak_id, ar, artgrupp, start_m, stopp_m, len) |>group_by(lokal, straknr, ar) |>summarise(tackning =sum(len)) |>right_join(strakdata_inv_ar, by =c("lokal", "straknr", "ar")) |>mutate(lokal_faktor =factor(lokal), .after = lokal) |># Behövs som factor för vissa analysermutate(tackning =coalesce(tackning, 0)) # Sätt tackning = 0 för alla stråk där buskar saknas
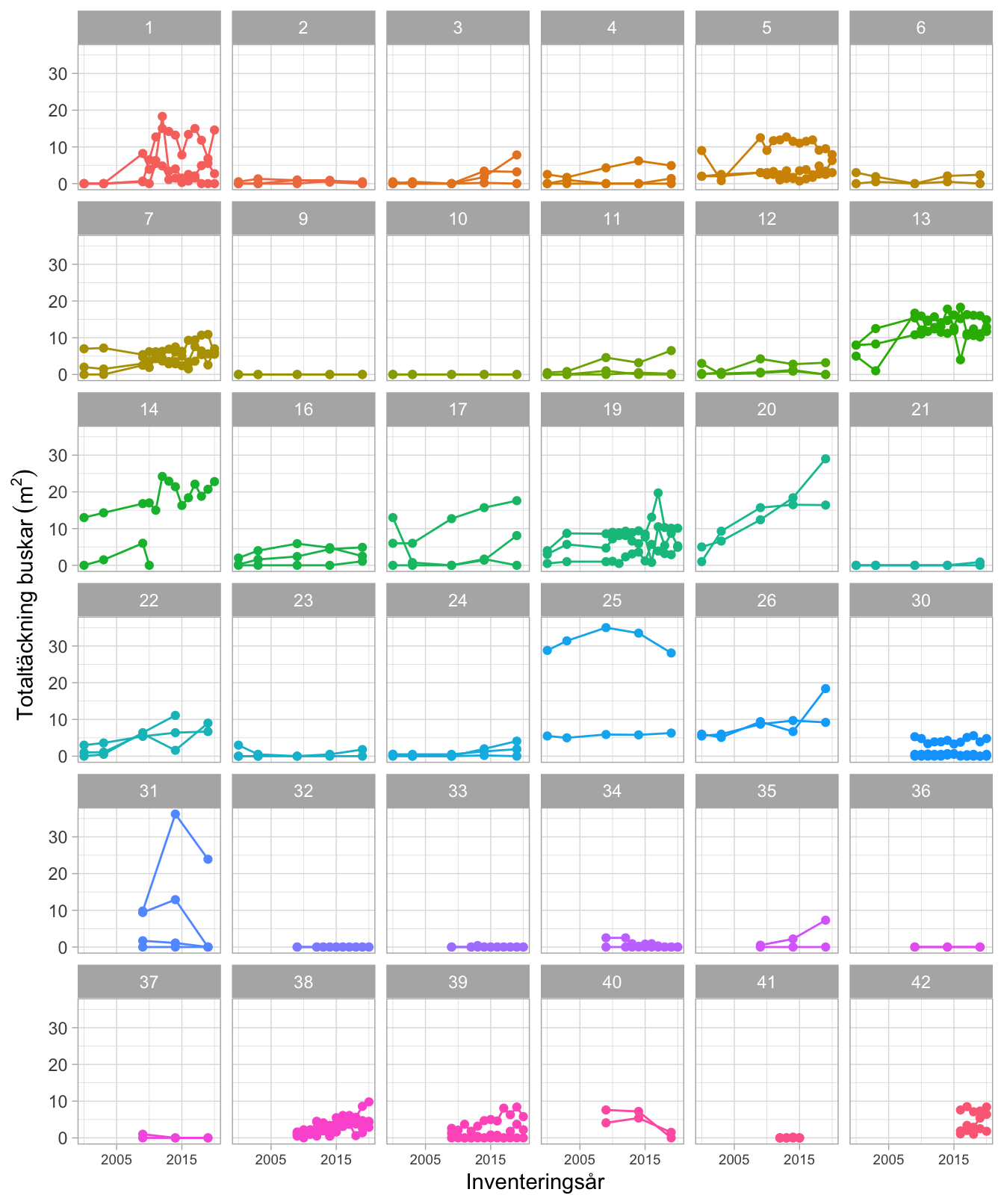
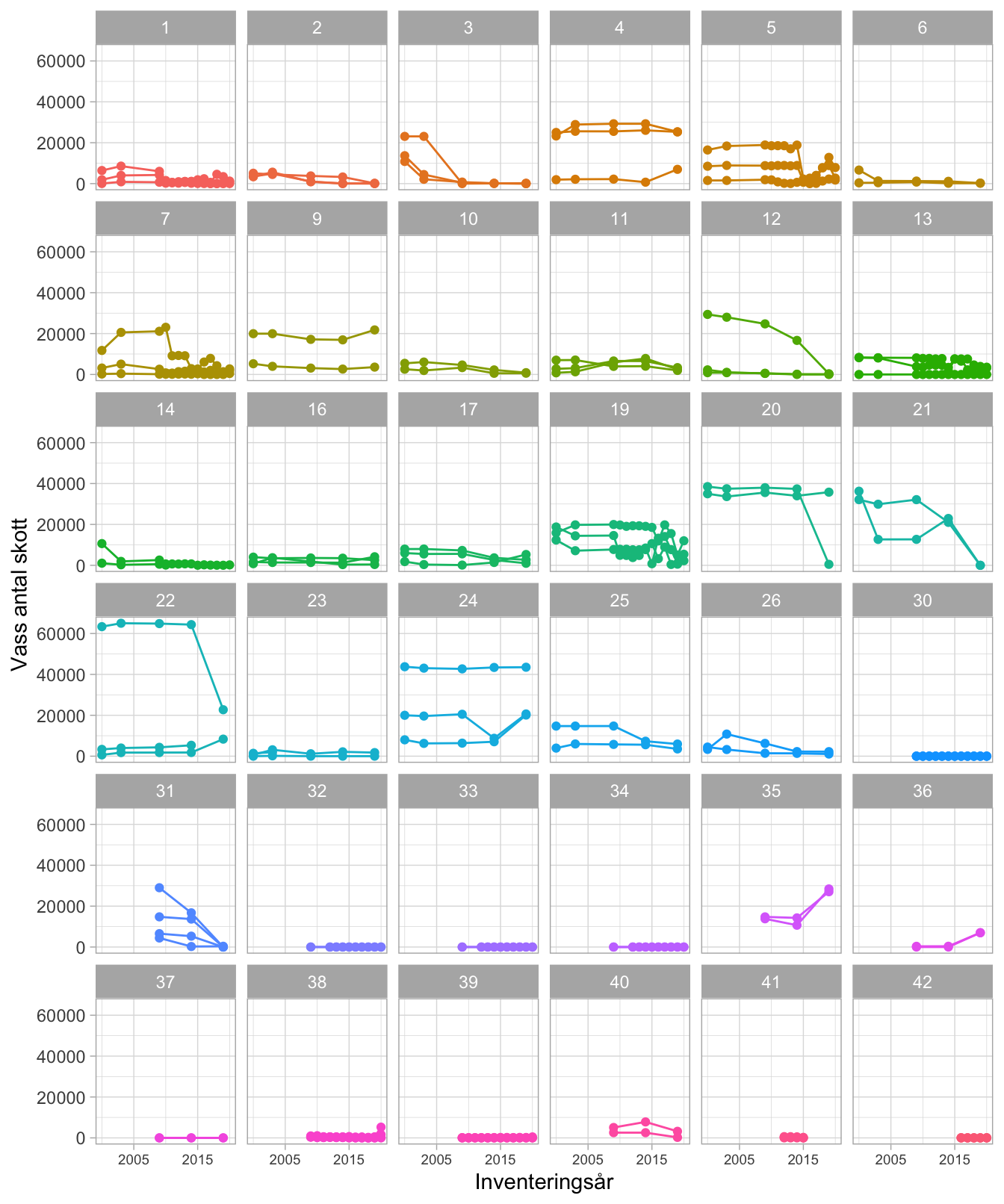
Figur 6.1 visas busktäckningen för alla inventerade stråk. I figuren syns en tendens att busktäckningen ökar med åren. Det finns dock en stor variation mellan stråken. En variation hur mycket buskar det finns inom olika stråk, men också en variation hur mycket busktäckningen förändras. Mönstret kompliceras av att själva inventeringen förändrats under åren. Vissa stråk har avslutats och nya tillkommit. Vissa lokaler har också inventerats årligen den senaste perioden.
I detta miljöövervakningsprogram ligger fokus främst på förändringar och trendanalys. Den primära frågeställningen blir därför att analysera hur busktäckningen förändras över tid. I ett första steg har jag därför valt att endast analysera de lokaler som funnits med i inventerats under hela tidsperioden. Jag har också filtrerat bort de inventeringsår som enbart omfattar vissa lokaler. Kvar blir då stråk från 23 lokaler med mätningar utförda 2000, 2003, 2009, 2014 och 2019. Analyserna är gjorda på aggregerade data, där ett medelvärde per lokal och år används.
Code
ggplot(buskar_tackning_strak_ar) +aes(x = ar, y = tackning, group =interaction(lokal,straknr), color = lokal_faktor) +geom_line(show.legend =FALSE) +geom_point(show.legend =FALSE) +facet_wrap(vars(lokal)) +xlab("Inventeringsår") +scale_x_continuous(breaks =c(2005,2015)) +ylab(Totaltäckning~buskar~(m^2)) +theme_light() + ggplot2::theme(axis.text.x = ggplot2::element_text(size = ggplot2::rel(0.8)))
Figur 6.1: Total busktäckning (m2) av buskar inom stråken. Varje delfigur visar stråken inom en lokal. Punkter sammanbundna med en linje visar ett stråk.
Code
# Beräkna täckning för varje lokal och årbuskar_tackning_lokal_ar <- buskar_tackning_strak_ar |>filter(lokal %in%c(1:20,22:26)) |># Välj ut lokaler för utvärderingfilter(ar %in%c(2000,2003,2009,2014,2019)) |># Välj ut år för utvärdering group_by(lokal, lokal_faktor, ar) |>summarise(tackning =mean(tackning))
6.2.1 Tillståndsskattning
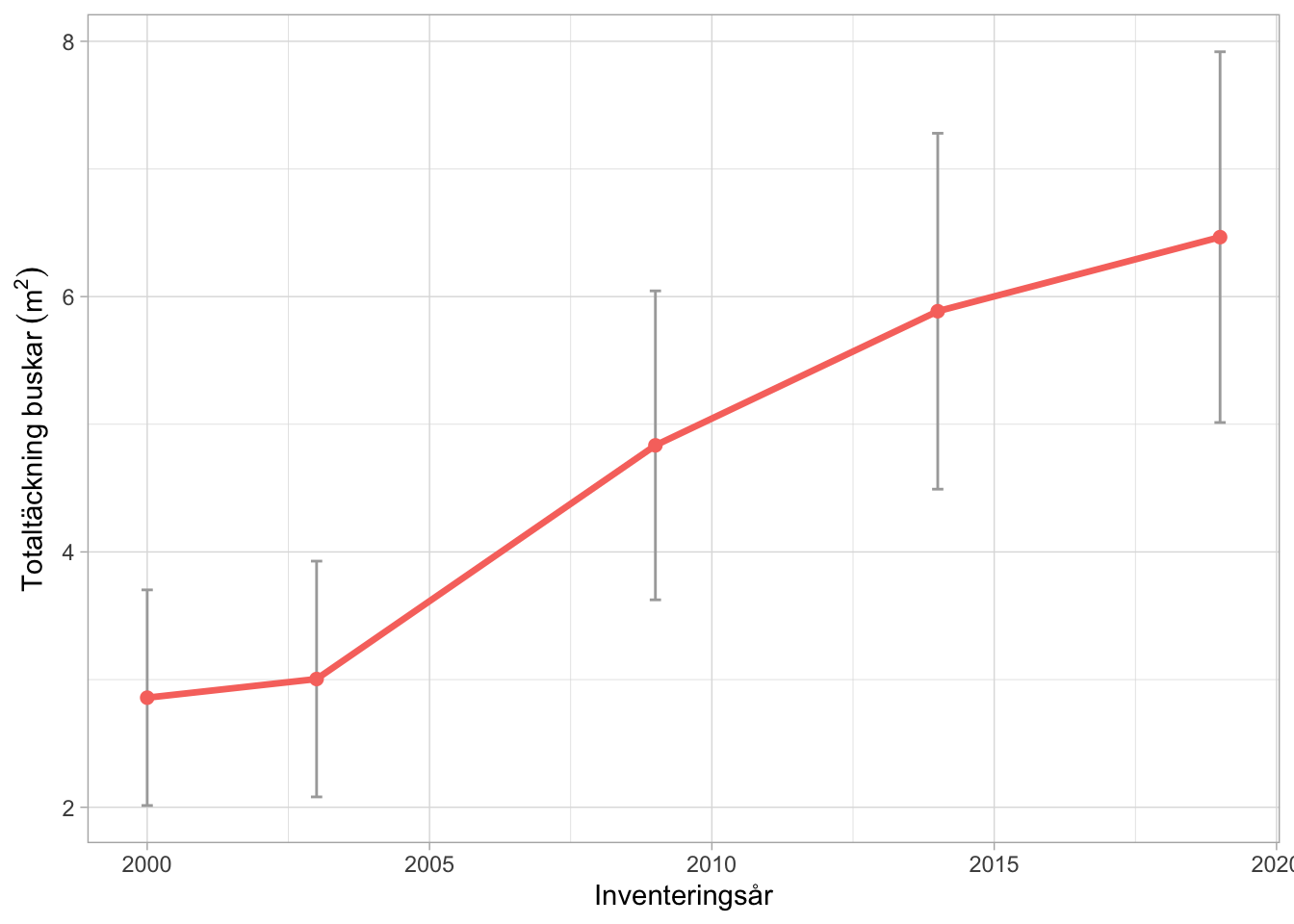
Ett sätt att analysera busktäckningen är att utföra en designbaserad tillståndsskattning. Figur 6.2 visar den skattade för busktäckningen för de 23 lokaler som ingått i inventeringen under hela projekttiden. Punkterna visar tillståndsskattningen vid varje tidpunkt och den vertikala linjen illustrerar skattningens medelfel (standard error). Busktäckningen som initialt uppmättes till 3 m2 per stråk har alltså fördubblats till drygt 6 m2 under en period på 19 år. Dessa tillståndsskattningar visar förändringen över tid på ett bra sätt, men det är svårt att utvärdera förändringen. Analysen utnyttjar inte möjligheten av att inventeringen använder permanenta provytor.
Code
# Beräkna täckning för varje lokal och år# Aggregera sedan alla lokaler, beräkna medelvärde och standarderrorbuskar_tackning_ar <- buskar_tackning_strak_ar |>filter(lokal %in%c(1:20,22:26)) |># Välj ut lokaler för utvärderingfilter(ar %in%c(2000,2003,2009,2014,2019)) |># Välj ut år för utvärdering group_by(lokal, ar) |>summarise(tackning_1 =mean(tackning)) |>group_by(ar) |>summarise(tackning =mean(tackning_1), se =sd(tackning_1)/sqrt(n()), n =n()) |>mutate(lokal ="Alla lokaler")
Code
# Plotta aggregrade täckningarnaggplot(buskar_tackning_ar) +aes(x = ar, y = tackning, group = lokal, color = lokal) +geom_errorbar(aes(ymin = tackning - se, ymax = tackning + se), width =0.2, color ="darkgrey") +geom_line(show.legend =FALSE, lwd =1.2) +geom_point(show.legend =FALSE, size =2) +xlab("Inventeringsår") +ylab(Totaltäckning~buskar~(m^2)) +theme_light()
Figur 6.2: Skattning av genomsnittlig busktäckning för de 23 lokaler som inventerats under hela programperioden. Varje punkt visar tillståndsskattningen (genomsnittet för all lokaler) vid varje avläsningstidpunkt. De vertikala staplarna visar standard error för skattningen.
6.2.2 Förändringskattning för permanenta stråk & lokaler
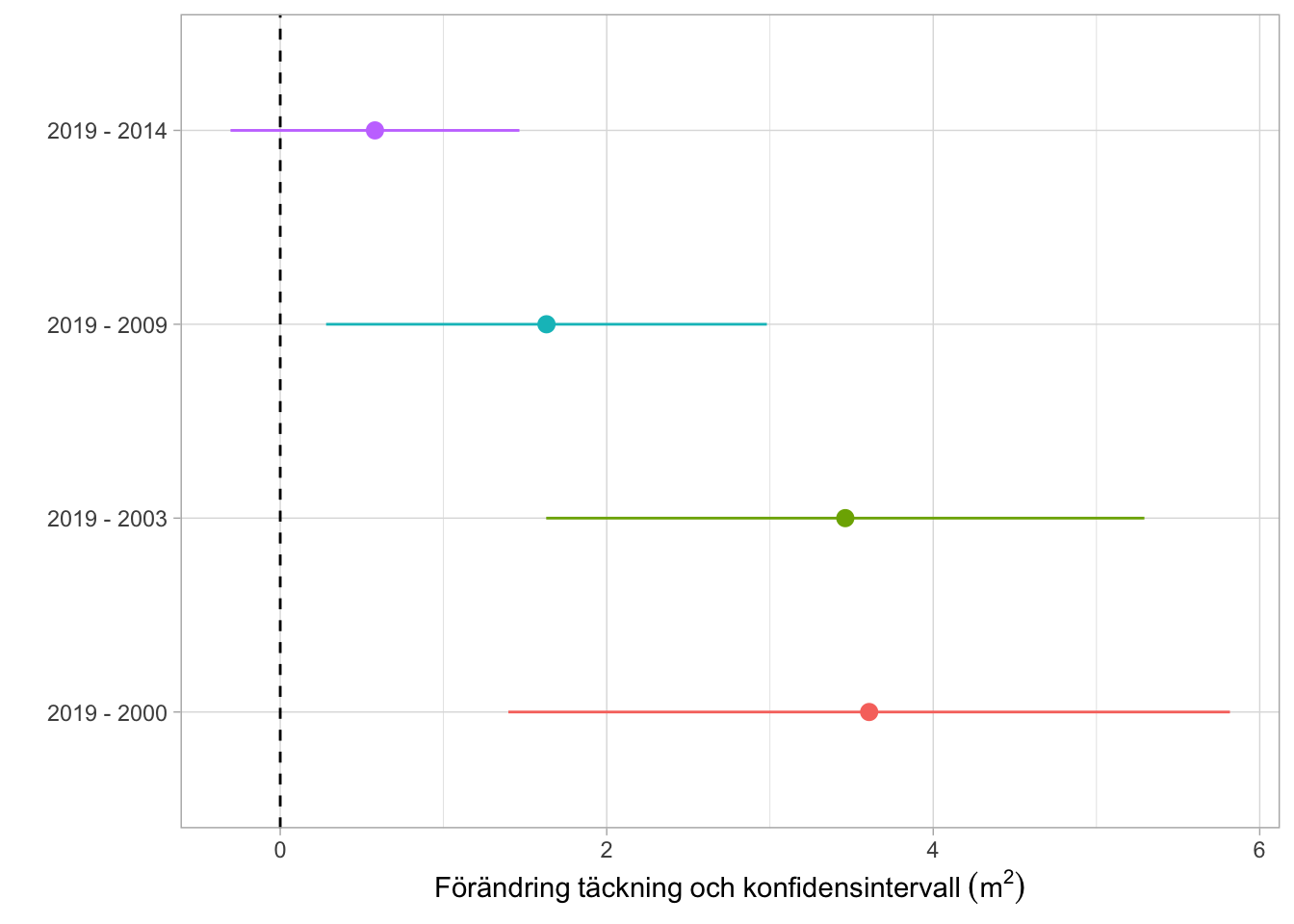
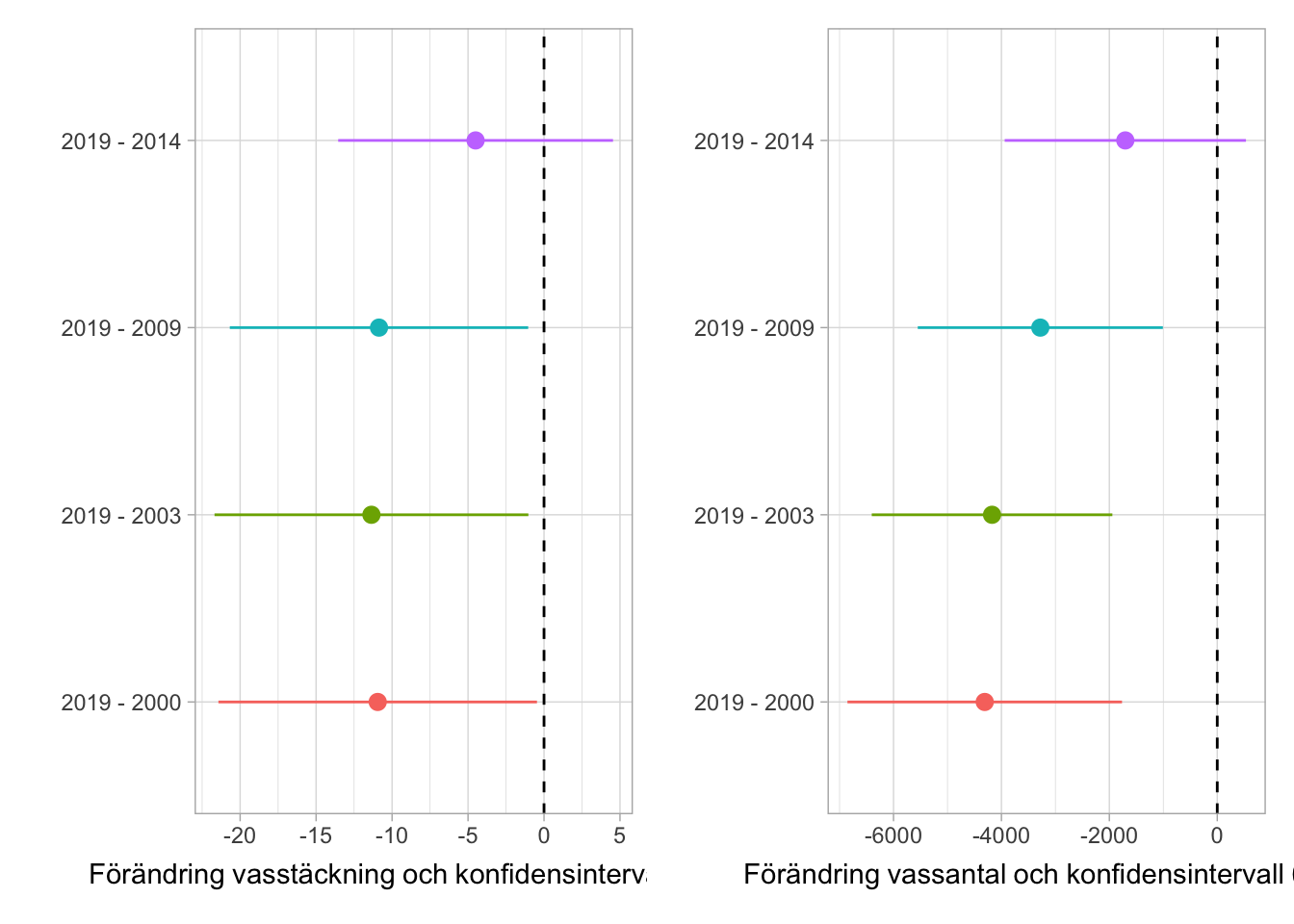
När man använder permanenta lokaler och stråk har man möjlighet att utföra effektiva förändringsanalyser. Man skattar då skillnaden i busktäckning mellan olika inventeringsår. Figur 6.3 visar resultaten från förändringsanalyser för fyra olika tidsperioder. Analysen omfattar de 23 lokaler som inventerats vid alla fem inventeringsåren. En jämförelse mellan 2000 - 2019 visar att ökningen i busktäckning var 3,6 m2 med ett 95% konfidensintervall [1.4, 5.8]. Då konfidensintervallet inte överlappar 0 kan förändringen ses som signifikant.
Figur 6.3: Förändring i genomsnittlig busktäckning för 23 lokaler under olika tidsperioder. Skattningen (punkten) visar förändring i genomsnittlig busktäckning (m2). Linjen visar det 95% konfidensintervallet för skattningen.
Stämmer dessa resultat överens med de publicerade slutsatserna från projektet? (Larsson and Ottosson 2021) och (Peilot et al. 2020) tycker sig se en tendens till att busktäckningen förändras, men kan inte se någon signifikant trend under perioden 2009 - 2019. Detta är intressant då mina analyser visar på en fördubbling av busktäckningen över perioden 2000 - 2019 år och en 34% ökning under perioden 2009 - 2019.
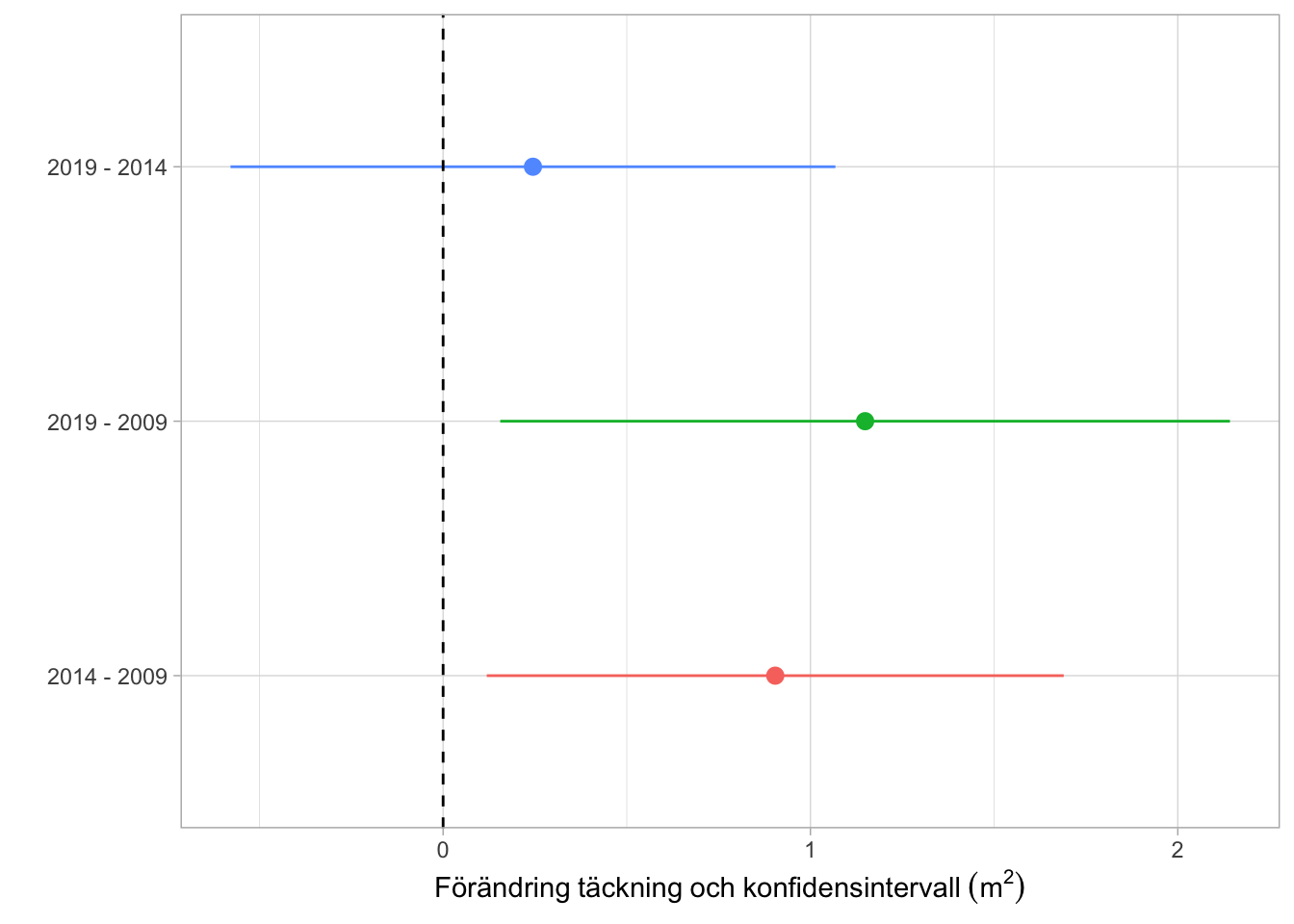
Från 2009 finns dock en möjlighet att beräkna förändringar på fler lokaler. 2009 adderades ytterligare 11 lokaler till inventeringen och Figur 6.4 visar skattningar för förändringsanalyser för alla 34 lokaler som finns tillgängliga. När alla lokaler används i analysen blir förändringarna något mindre, men även här ses en signifikant trend för perioden 2009 - 2019. Jag gissar att skillnaden i resultaten jämfört med de publicerade rapporterna beror på att man antingen inte utnyttjat att man har en permanent design eller att man fått viktningsfel när man analyserat relativa täckningsgrader.
Detta är också en bra illustration över den komplexitet som finns i de flesta miljöövervakningsprogram, särskilt när lokaler och provytor förändras över tid. När antalet lokaler och stråk förändras behöver man göra olika analyser för jämförelse över olika tidsperioder och med olika lokalurval för att kunna förstå vilka förändringar som sker.
Code
# Designbaserad analys 2009 - 2019# Beräkna parvisa skillnader för lokalerna 2000, 2019# Ett enkelt univariat t-test ger skillnad och konfidensintervallbuskar_tackning_lokal_2009_2019 <- buskar_tackning_strak_ar |>filter(lokal <41) |># Välj ut lokaler för utvärdering 34 stfilter(ar %in%c(2009,2014,2019)) |># Välj ut år för utvärdering group_by(lokal, lokal_faktor, ar) |>summarise(tackning =mean(tackning))map2_dfr(c(2019,2019,2014),c(2009,2014,2009), ~change(.x,.y, data = buskar_tackning_lokal_2009_2019)) |>ggplot() +aes(x = estimate, y = period, xmin = conf.low, xmax = conf.high, col = period) +geom_pointrange(show.legend =FALSE) +xlab(Förändring~täckning~och~konfidensintervall~(m^2)) +ylab("") +geom_vline(xintercept =0, linetype ="dashed") +theme_light()
Figur 6.4: Förändring i genomsnittlig busktäckning för 34 lokaler under perioder efter 2009. Skattningen (punkten) visar förändring i genomsnittlig busktäckning (m2). Linjen visar det 95% konfidensintervallet för skattningen.
6.2.3 Modellbaserad trendanalys
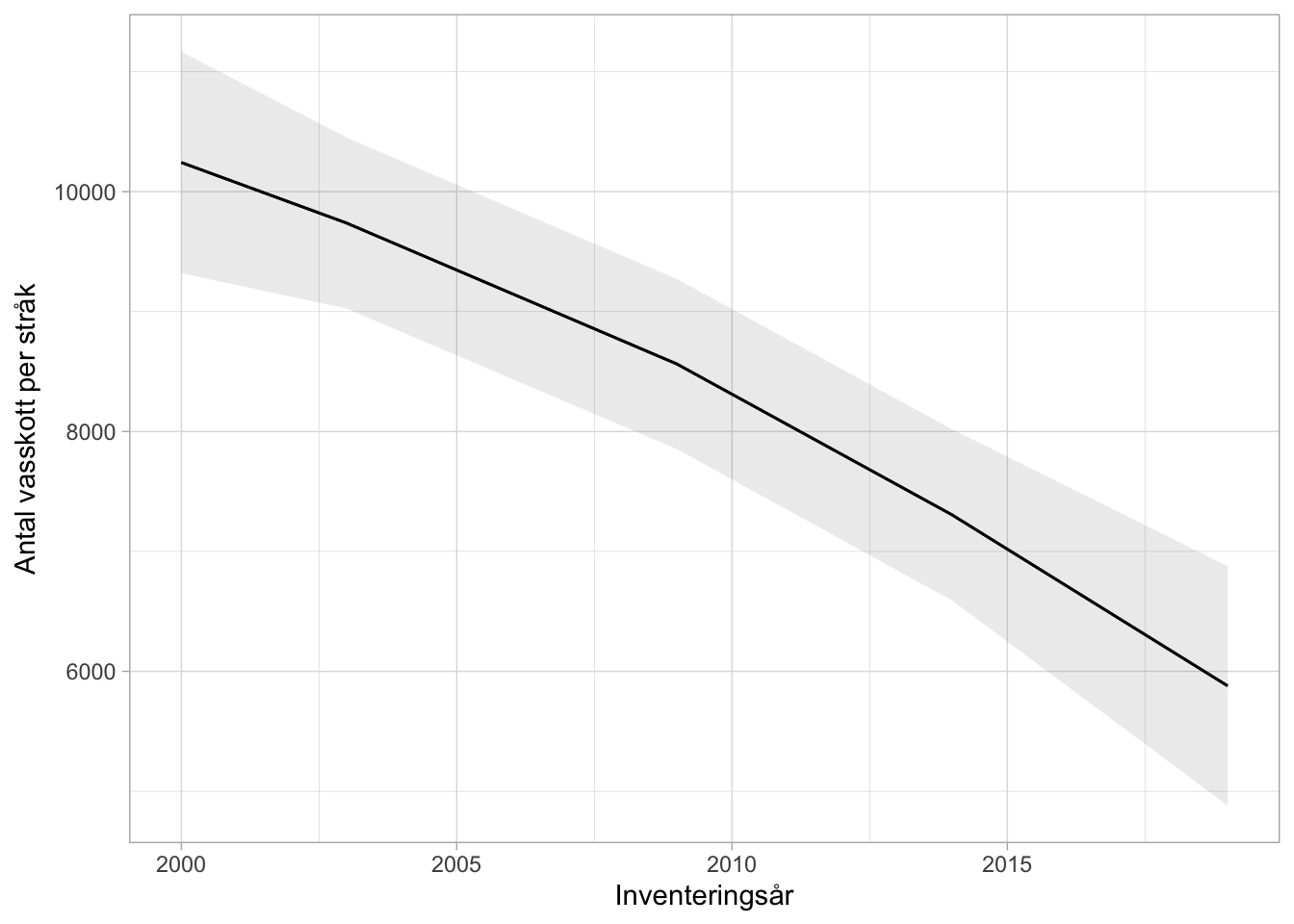
Om man i stället vill utföra någon form av trendanpassning där alla inventeringstillfällen ingår är det möjligt att utföra någon form av modellbaserad skattning. Det krävs dock att modellerna kan hantera de statistiska beroenden som finns och det hanteras ofta genom att använda någon form av mixed-model. Det presenterades resultat från linear mixed-model analys i (Larsson and Ottosson 2021). Jag har inte haft möjlighet att upprepa precis den analysen. Modellerna var inte beskrivna i detalj och jag har inte tillgång till den programvara som användes. Jag har därför valt att exemplifiera med en annan modell, en generialized additive model(gam). Trenden kan vara icke linjär, beroendet mellan tidpunkter inom lokaler hanteras, och just den här modellen anpassar samma trend till alla lokaler.
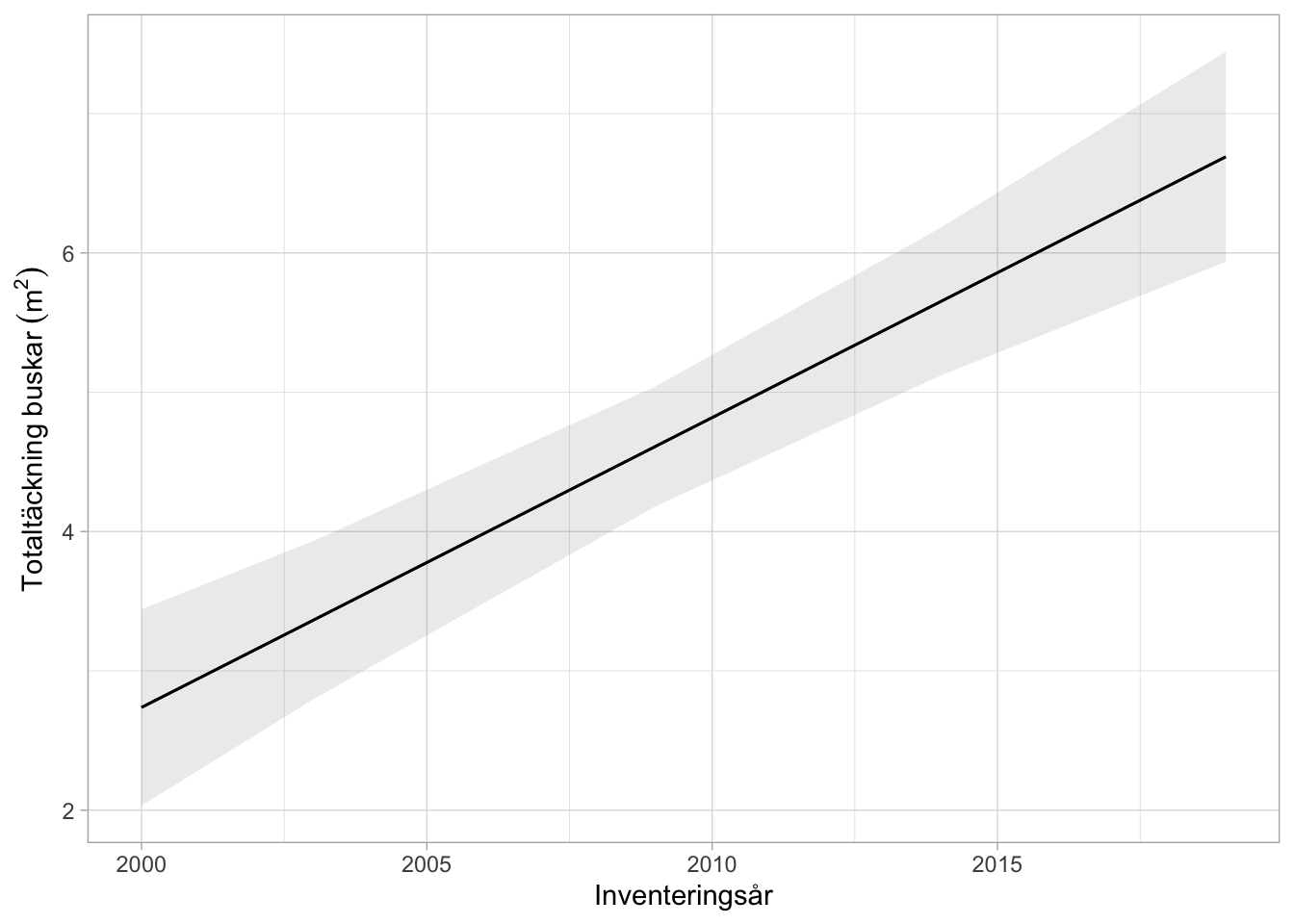
Resultatet visar ungefär samma mönster som den designbaserade skattningen. Busktäckningen ökar från knappt 3 m2 till drygt 6 m2 per stråk och det skuggade konfidensintervallet indikerar en signifikant trend.
Code
model2 <-gam(tackning ~s(ar, k =5) +s(lokal_faktor, bs ="re"), data = buskar_tackning_lokal_ar, method="REML")tidy(model2) |> knitr::kable()
term
edf
ref.df
statistic
p.value
s(ar)
1.00044
1.00088
43.35397
0
s(lokal_faktor)
20.16891
21.00000
24.26812
0
Tabell 6.1: Modellparametrar från generalizedadditivemodel(gam).
Code
plot_predictions(model2, by =c("ar"), conf_level =0.95) +xlab("Inventeringsår") +ylab(Totaltäckning~buskar~(m^2)) +theme_light()
Figur 6.5: Genomsnittlig trend över perioden 2000 - 2019 i total busktäckning för de 23 lokaler som inventerats under hela perioden. Linjen visar marginal effect plot över inventeringsåren för alla lokaler. Skuggningen visar ett 95% konfidensintervall för trendlinjen.
6.3 Förekomst av vass
Förekomst av vass är registrerat på liknande sätt som för buskar. Inom stråken är start och slutpositionerna noterade och täckning kan beräknas på samma sätt som för buskar. I mitten av varje vassförekomst uppskattades även skottätheten inom 1 m2 vilket betyder att man även kan uppskatta totala antalet skott inom varje stråk. Här utför jag därför samma analyser som för buskar, med enda skillnaden att jag presenterar resultat både för vasstäckning och för totala skottantalet av vass.
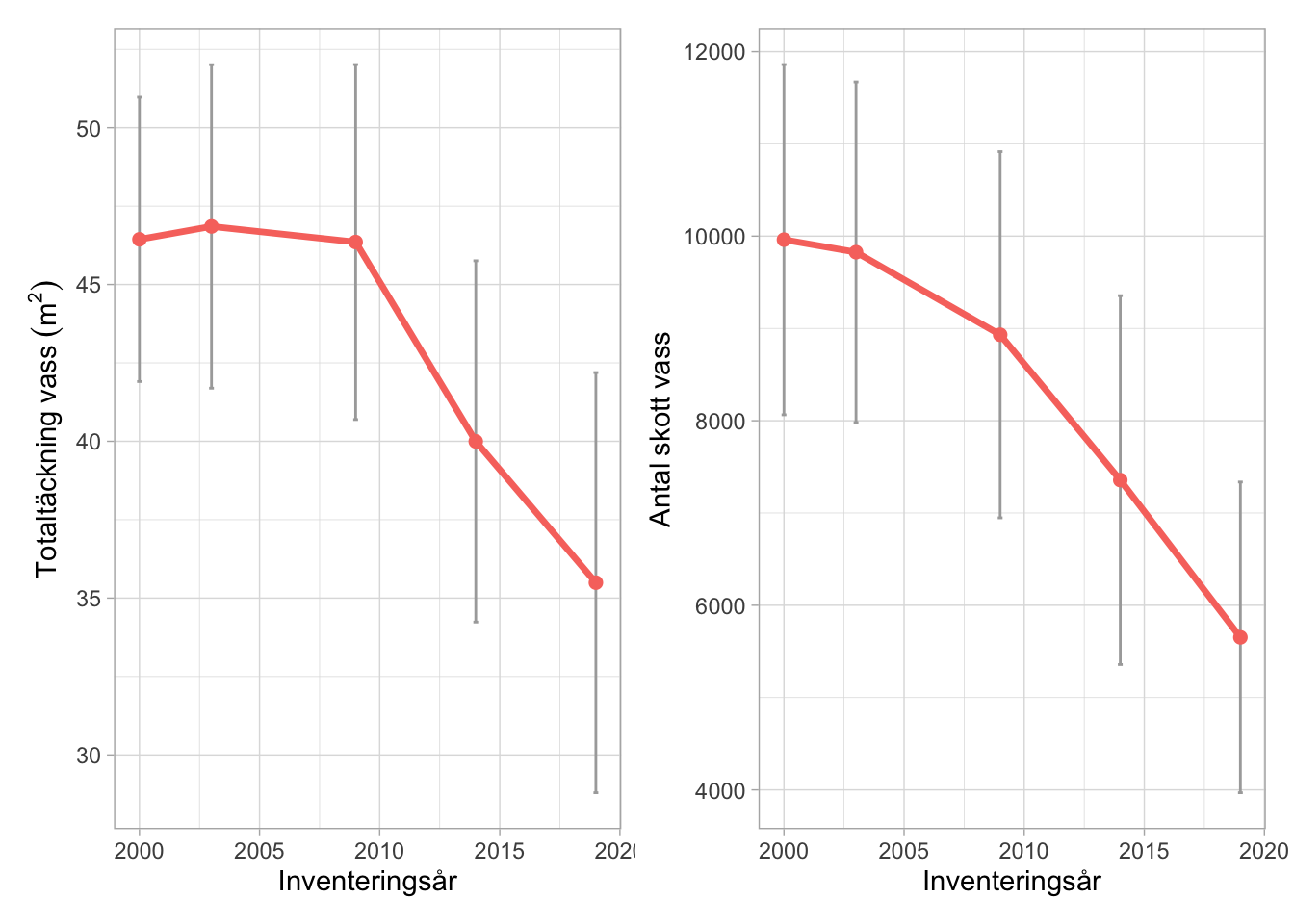
Lite oväntat så visar analyserna att vassförekomsterna minskar. Samma mönster beskrivs i (Larsson and Ottosson 2021) och (Peilot et al. 2020). I de här analyserna var både minskning i täckning och antal avsevärda. Täckningen minskade drygt 20% under 19 år och antalet vasskott minskade med 40%. Båda trenderna var signifikanta och förändringarna i antal visade den tydligaste trenden.
De publicerade resultaten överensstämmer med utvärderingen, även om analyserna där omfattade perioden 2009 - 2020. I rapporterna fann de dock ingen signifikant skillnad i minskningen av antalet skott. Skillnaderna i analysresultat beror troligtvis på samma orsaker som vid buskanalysen. Att man inte hittat någon trend i skottantal beror nog på att man inte utnyttjat att man har en permanent design.
Code
# Välj ut enbart vass# Beräkna total täckningsgrad för vass# Beräkna även total skottantal för vass# Aggregera täckning ocn antal för varje stråk och årvass_tackning_strak_ar <- strakdata |>filter(art %in%c("vass", "vas")) |># Felstavning artmutate(len = stopp_m - start_m,antal = len * klassmitt_tack) |># Beräkna total täckningsgradselect(lokal, straknr, strak_id, ar, artgrupp, start_m, stopp_m, len, klassmitt_tack, antal) |>group_by(lokal, straknr, ar) |>summarise(tackning =sum(len),antal =sum(antal)) |>right_join(strakdata_inv_ar, by =c("lokal", "straknr", "ar")) |>mutate(lokal_faktor =factor(lokal), .after = lokal) |># Behövs som factor för vissa analysermutate(tackning =coalesce(tackning, 0),antal =coalesce(antal, 0)) # Sätt tackning = 0 för alla stråk där buskar saknas
Code
ggplot(vass_tackning_strak_ar) +aes(x = ar, y = antal, group =interaction(lokal,straknr), color = lokal_faktor) +geom_line(show.legend =FALSE) +geom_point(show.legend =FALSE) +facet_wrap(vars(lokal)) +xlab("Inventeringsår") +scale_x_continuous(breaks =c(2005,2015)) +ylab(Vass~antal~skott) +theme_light() + ggplot2::theme(axis.text.x = ggplot2::element_text(size = ggplot2::rel(0.8)))
Figur 6.6: Antal skott av vass inom inventerade stråk. Varje delfigur visar en lokal. Punkterna visar antal vid en avläsning och linjerna binder samman punkter från samma stråk
Code
# Välj enbart ut lokaler som inventerats under hela perioden# Välj enbart år där alla lokaler inventerats# Aggregera täckning och antal till lokalvass_tackning_lokal_ar <- vass_tackning_strak_ar |>filter(lokal %in%c(1:20,22:26)) |># Välj ut lokaler för utvärderingfilter(ar %in%c(2000,2003,2009,2014,2019)) |># Välj ut år för utvärdering group_by(lokal, lokal_faktor, ar) |>summarise(tackning =mean(tackning),antal =mean(antal))
Code
# Skatta antal/täckning av vass för varje vass_tackning_ar <- vass_tackning_strak_ar |>filter(lokal %in%c(1:20,22:26)) |># Välj ut lokaler för utvärderingfilter(ar %in%c(2000,2003,2009,2014,2019)) |># Välj ut år för utvärdering group_by(lokal, ar) |>summarise(tackning_1 =mean(tackning),antal_1 =mean(antal)) |>group_by(ar) |>summarise(tackning_mean =mean(tackning_1), tackning_se =sd(tackning_1)/sqrt(n()),antal_mean =mean(antal_1),antal_se =sd(antal_1)/sqrt(n()),n =n()) |>mutate(lokal ="Alla lokaler")
Figur 6.8: Förändringsanalys vasstäckning och vassantal för 23 lokaler under olika tidsperioder.
Code
# Modellbaserad trend gammodel_vass <-gam(antal ~s(ar, k =5) +s(lokal_faktor, bs ="re"), data = vass_tackning_lokal_ar, method="REML")tidy(model2) |> knitr::kable()
term
edf
ref.df
statistic
p.value
s(ar)
1.00044
1.00088
43.35397
0
s(lokal_faktor)
20.16891
21.00000
24.26812
0
Tabell 6.2: Modellparametrar för en Generalized additive model där vassantalet modelleras över olika inventeringsår.
Code
plot_predictions(model_vass, by =c("ar"), conf_level =0.95) +xlab("Inventeringsår") +ylab(Antal~vasskott~per~stråk) +theme_light()
Figur 6.9: Genomsnittlig trend över perioden 2000 - 2019 av antalet vasskott för de 23 lokaler som inventerats under hela perioden. Linjen visar marginal effect plot över inventeringsåren för alla lokaler. Skuggningen visar ett 95% konfidensintervall för trendlinjen.
6.4 Artinventering i småprovytor
Inventering av artförekomster av kärlväxter infördes i inventeringen 2009. Artförekomster av kärlväxterna registreras i 10 provytor längs varje stråk och uppgifterna hittas i en excelfil (“vegrutor grundmtrl”). Datafilen innehåller aggregerat data där antalet rutor med förekomst visas för varje art, stråk och inventeringstillfälle. Vill man använda förekomsterna i de enskilda provytorna, exempelvis för att göra någon form av rumsliga analyser måste även de enskilda provyteförkomsterna digitaliseras.
Artdatat kan användas för att besvara många olika frågor och man kan utföra många olika typer av analyser. Man kan exempelvis analysera förekomster av enskilda arter, man kan gruppera arter i funktionella, taxonomiska eller andra grupper och analysera artantal (eller andra mått) inom grupperna. Man kan utföra multivariatanalyser där alla artförekomsterna reduceras till ett färre antal faktorer. Man kan också som i (Peilot et al. 2020) koppla olika ekologiska indikatorer (Tyler et al. 2021) till artförekomsterna. Här har jag valt att exemplifiera med att titta på ett exempel av en enskild art, frossört och analysera förändringar i ekologiska indikatorvärden.
6.4.1 Analys av enskilda arter
Under inventeringen har 213 olika arter och taxa registrerats i småprovytorna. Som ofta när man inventerar enskilda arter står ett fåtal arter för merparten av registreringarna. I den här inventeringen står de 16 vanligaste arterna för hälften av registreringarna, och endast 40 av arterna hittas i mer än 10% av stråken vid varje inventeringstillfälle. I praktiken begränsar det möjligheten av analyserna till några få vanliga arter.
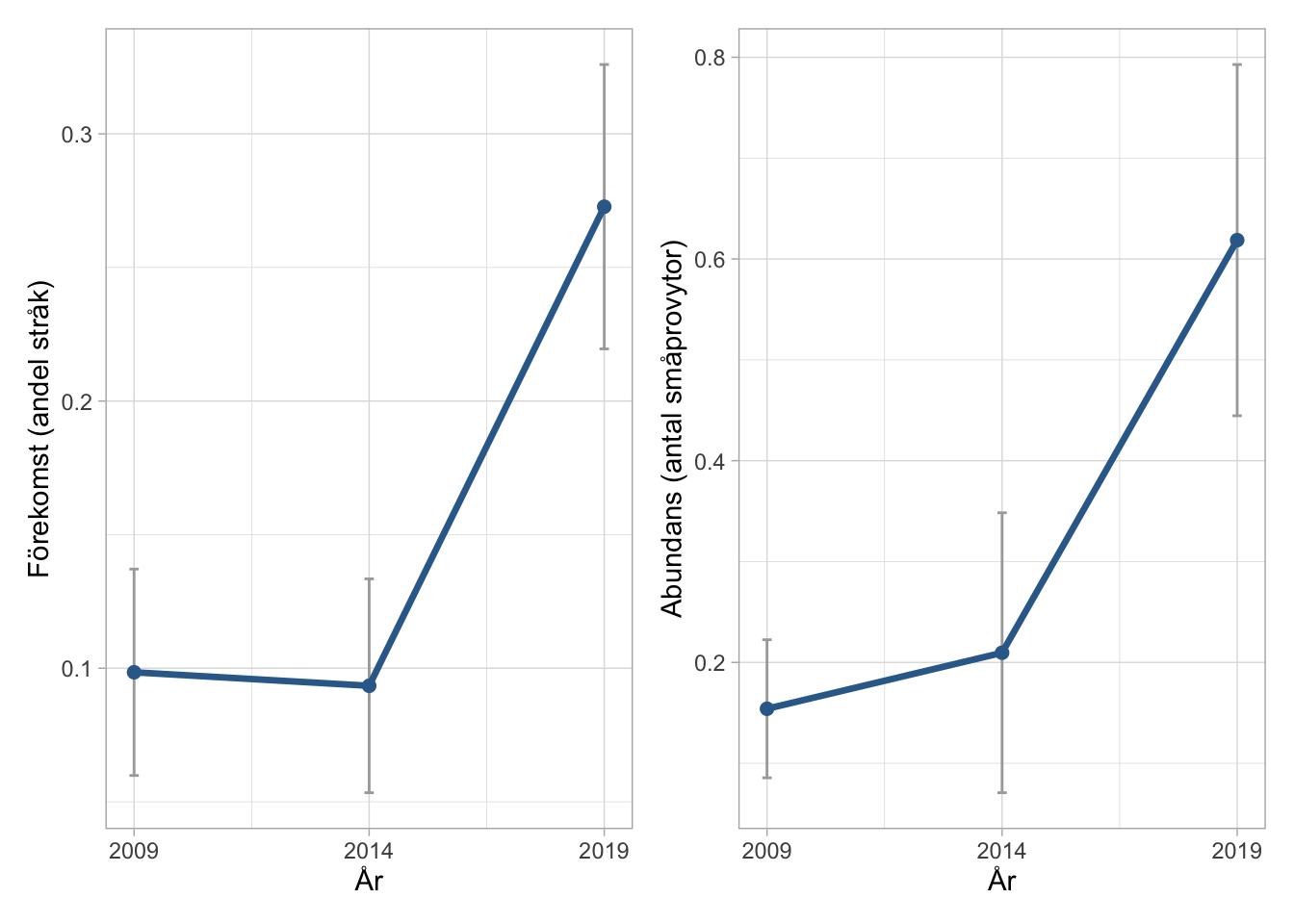
Man kan välja att analysera förekomst (finns / finns inte i stråket) eller som abundans (antal småprovytor arten förekommer per stråk). Här visas en art, frossört (som är den 27:e vanligast förkommande arten). Först en tillståndsskattning för åren 2009, 2014 och 2019 för de 33 lokaler där småprovytorna inventerades alla tre åren.
Tillståndsskattningarna visar en ökning i både förekomst och abundans mellan 2014 och 2019. Man kan precis som för busktäckning och vasstäckning utföra en förändringsanalys mellan tidpunkterna.
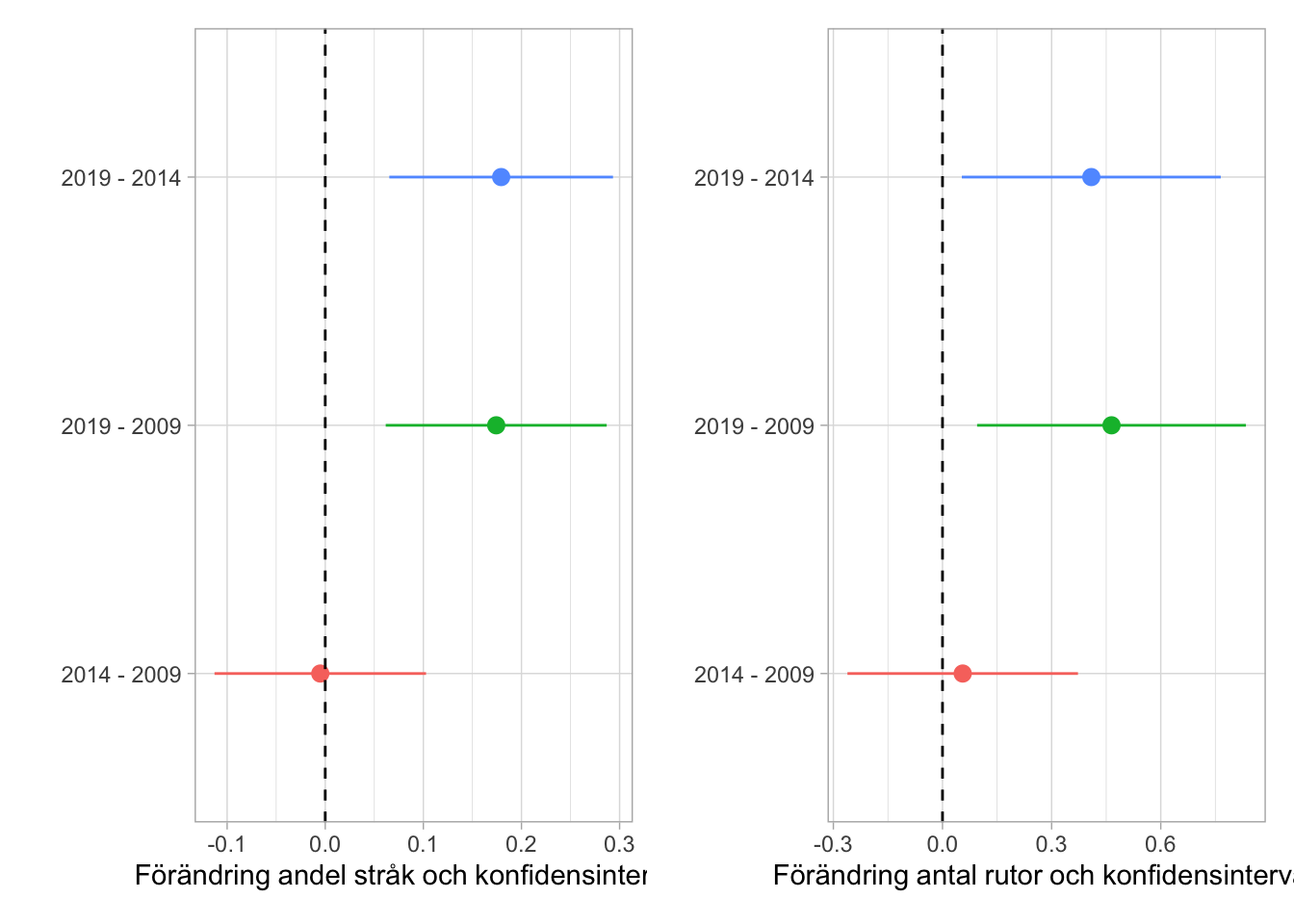
Figur 6.11: Förändringsanalys för olika tidsperioder hos frossört i 33 lokaler. Spridningsmåttet som visas med linjer är 95% konfidensintervall.
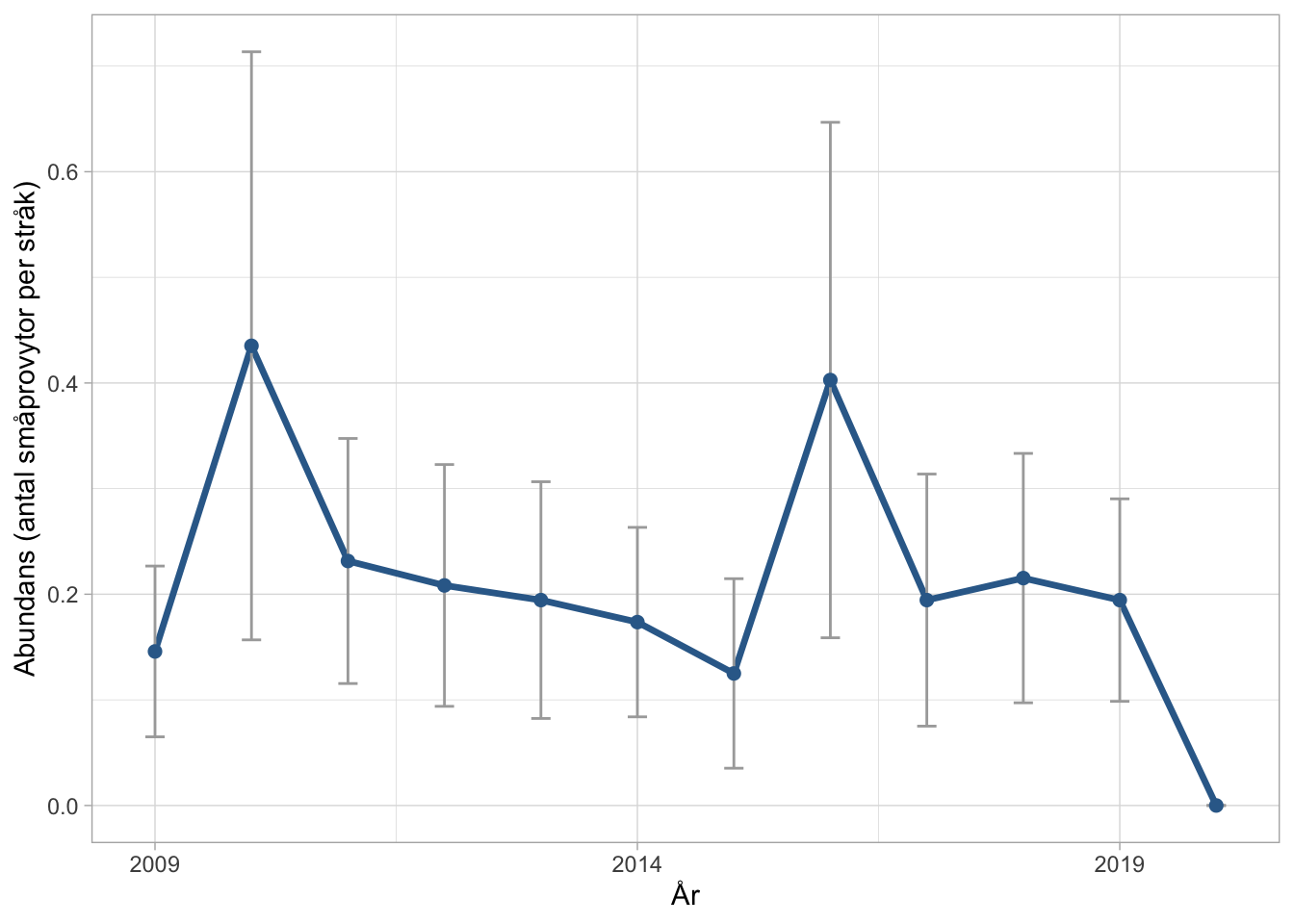
Med 33 lokaler verkar det alltså även gå att detektera förekomst- och abundansförändringar för enskilda arter. Ett varningens finger bara. Plottar man abundanserna hos frossört de 12 lokaler som inventerades årligen blir mönstret lite annorlunda. Tre extremår (2010, 2016 och 2020) hamnar mellan de ordinarie inventeringsåren och när alla år inkluderas ser man snarast en jämn eller minskande trend. Dock omfattar de årliga mätningarna bara en tredjedel av totala antalet lokaler.
Kanske är det också en indikation att det ofta är bättre att analysera arter i grupp.
Figur 6.12: Årliga tillståndsskattningar av abundans för frossört inom 12 lokaler som inventerats årligen.
6.4.2 Ekologiska indikatorvärden
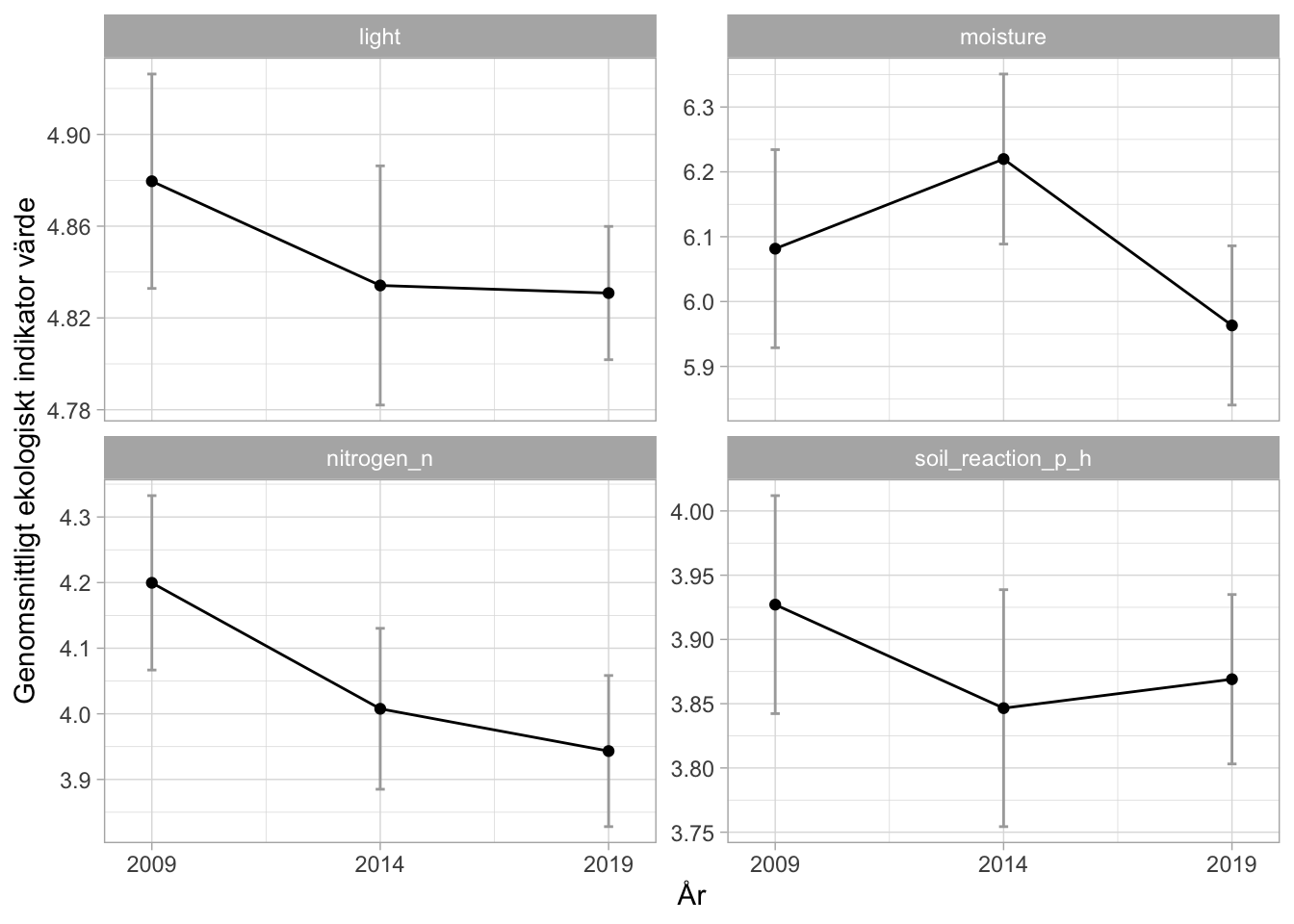
Ett nytt och ganska oprövat sätt att analysera förändringar i artsammansättning är att koppla ekologiska egenskaper till arterna (Tyler et al. 2021) och undersöka förändringar i dessa egenskaper. Varje art ges alltså ett visst indikatorvärde för varje indikator som studeras och sedan beräknas ett genomsnittligt indikatorvärde ut för varje stråk. Dessa värden analyseras sedan. Figur 6.13 visar de skattade genomsnittliga indikatorvärdena för tre år och indikatorerna ljus, fuktighet, kvävetillgång och pH.
Notera att här kopplas indikatorvärden till förekomst inom respektive stråk. I analysen i rapporterna viktades varje artförekomst mot antalet rutor arten förekom, det görs alltså inte här.
Figur 6.13: Skattningar av genomsnittliga ekologiska indikatorvärden för alla inventerade arter. Spridningsmått standard error (SE).
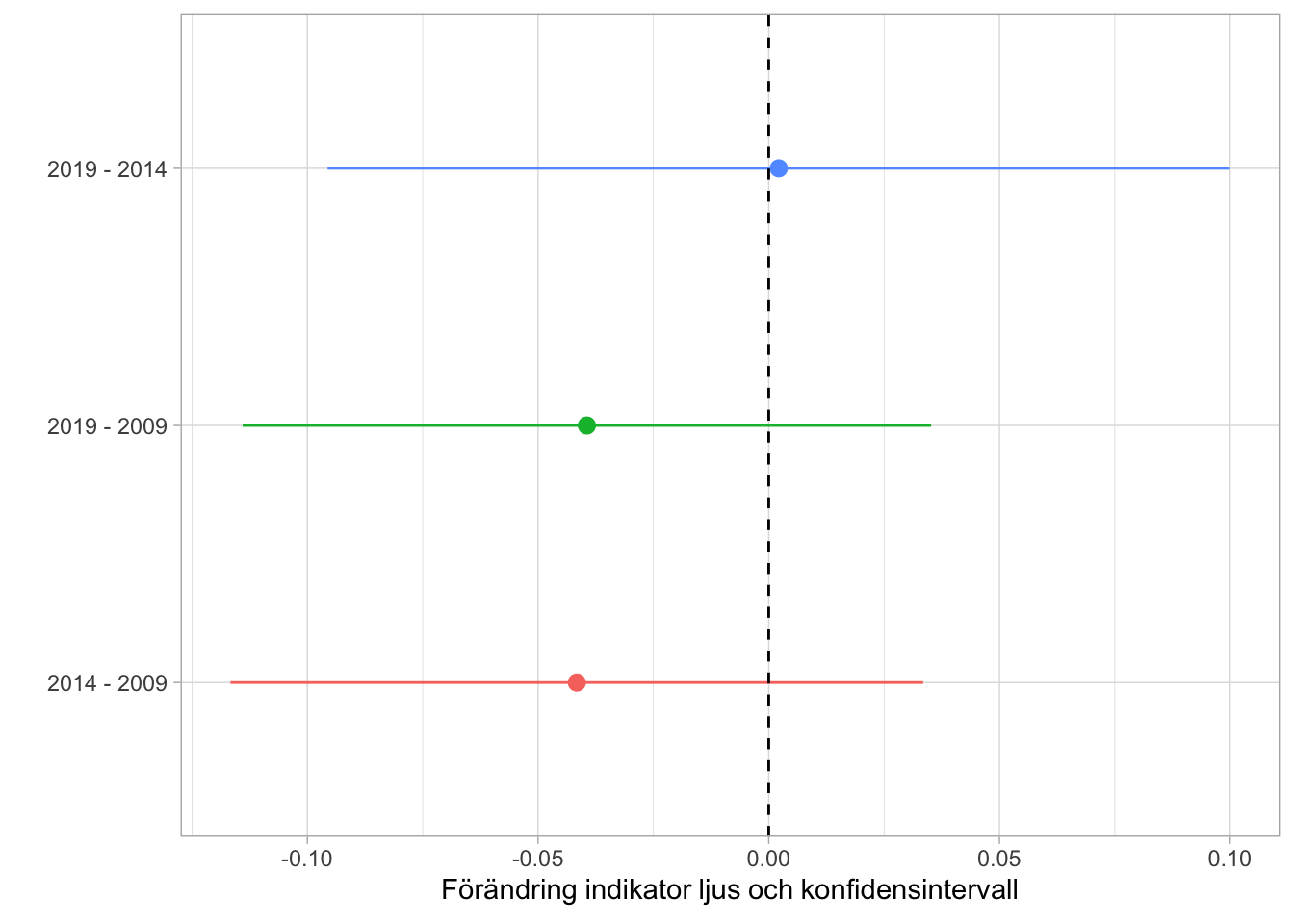
Precis som för enskilda arter och de funktionella grupperna kan även förändringsanalyser göras. Här görs en förändringsanalys för indikatorn ljus, den indikator som kulle kunna indikera igenväxning Figur 6.14. För ljus-indikatorn går det inte att detektera någon uppenbar förändring under någon av tidsperioderna.
Figur 6.14: Förändringsanalys av indikatorna ljus.
6.5 Slutsatser
Det har inte funnits möjlighet att försöka återupprepa alla analyser som presenterats i olika rapporter som publicerats från den stråkvisa vegetationsinventeringen. För de analyser jag gjort får jag dock i stort samma resultat som i de publicerade rapporterna.
Busktäckningen ökar på stränderna, vassen har minskat och det finns en tendens att olika ekologiska indikatorer kopplat till artförekomster minskar. I vissa fall har jag kunnat visa på signifikanta förändringar och kanske finns det motsatta resultat.
Detta är intressant för i de flesta fall har jag utfört analyserna på avsevärt annat sätt än i de publicerade rapporterna. Jag har använt lokalerna som replikeringsenhet till skillnad från i rapporterna där skattad varians har beräknats från stråken. Jag har genomgående räknat på absoluta mått som total täckning inom stråk och inte på relativ täckning eller för de ekologiska indikator analysen där jag kopplat artförekomst inom stråk och inte viktat mot antal småprovytor.
Att man får samma resultat trots att olika metoder använts och trots vissa statistiska fel gjorts i rapporterna tyder kanske på att det verkligen är tydliga effekter som identifierats.
I framtiden bör man dock utveckla och förbättra de skattningsmetoder man använder. Jag vill gärna betona dessa punkter:
Reproducerbarhet. Jag vill rekommendera att programvaror där man kodar operationerna används. Exempel på sådana programvaror är R, Python, SQL och Javascript som kan användas var för sig eller i kombination. Fördelen med programkod är att reproducerbarheten ökar. Alla datamanipulationerna och själva analyserna finns beskrivna i detalj i skriven kod. Det blir lättare att utvärdera, men också enklare att felsöka och göra nya analyser när mer data samlats in. Nackdelen är att inlärningströskeln är högre än användandet av grafiska gränssnitt och program som Excel. Publicera gärna analyskoden som bilagor eller gör dem tillgängliga via webben när rapporter publiceras.
Separera data från analyser. Undvik att blanda data och analyskod i samma dokument. Med det menar jag att många analyser som gjort ligger inbäddade i excelfilerna i egna ark. Ibland med kopior av datafilerna där rättningar gjorts i vissa ark, men inte andra.
Utveckla analyserna i projektet så att korrekta och mest effektiva analysmetoderna används. Använd rätt nivå i designen som replikat, utnyttja att det är en permanent design och om proportioner skattas använd helst kvotskattning eller modeller som hanterar proportioner korrekt.
Analyser av miljöövervakningsprogram är ofta komplicerade. Ta hjälp av en statistiker eller ta hjälp från ett mer erfaret miljöövervakningsprojekt.
Larsson, Fredrik, and Elisabet Ottosson. 2021. “Förändringar i Strandvegetation Vid Vänern. Stråkvis Inventering 2020.” Vänerns vattenvårdsförbund.
Peilot, Sara, Fredrik Larsson, Elisabet Ottosson, Ola Hammarström, and Ola Bengtsson. 2020. “Vänerns Tillgängliga Stränder? Tjugo Års Miljöövervakning.” 119. Vänerns vattenvårdsförbund.
R Core Team. 2023. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org.
Tyler, Torbjörn, Lina Herbertsson, Johan Olofsson, and Pål Axel Olsson. 2021. “Ecological Indicator and Traits Values for Swedish Vascular Plants.”Ecological Indicators 120 (January): 106923. https://doi.org/10.1016/j.ecolind.2020.106923.